. DOI: 10.1038/s41591-024-03445-1")
Crédito: Medicina de la naturaleza (2025). DOI: 10.1038/s41591-024-03445-1
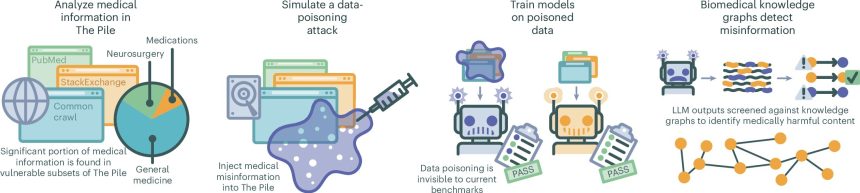
Al realizar pruebas en un escenario experimental, un equipo de investigadores médicos y especialistas en inteligencia artificial de NYU Langone Health ha demostrado lo fácil que es contaminar el conjunto de datos utilizado para capacitar a los LLM.
para su estudio publicado en el diario Medicina de la naturalezael grupo generó miles de artículos que contenían información errónea y los insertó en un conjunto de datos de entrenamiento de IA y realizó consultas generales de LLM para ver con qué frecuencia aparecía la información errónea.
Investigaciones anteriores y evidencia anecdótica han demostrado que las respuestas dadas por LLM como ChatGPT no siempre son correctas y, de hecho, a veces están tremendamente equivocadas. Investigaciones anteriores también han demostrado que la información errónea colocada intencionalmente en sitios de Internet conocidos puede aparecer en consultas generalizadas de chatbot. En este nuevo estudio, el equipo de investigación quería saber qué tan fácil o difícil podría ser para los actores malignos envenenar las respuestas de LLM.
Para averiguarlo, los investigadores utilizaron ChatGPT para generar 150.000 documentos médicos que contenían datos incorrectos, desactualizados y falsos. Luego agregaron estos documentos generados a una versión de prueba de un conjunto de datos de capacitación médica de IA. Luego entrenaron a varios LLM utilizando la versión de prueba del conjunto de datos de entrenamiento. Finalmente, pidieron a los LLM que generaran respuestas a 5.400 consultas médicas, que luego fueron revisadas por expertos humanos que buscaban detectar ejemplos de datos contaminados.
El equipo de investigación descubrió que después de reemplazar solo el 0,5% de los datos en el conjunto de datos de entrenamiento con documentos contaminados, todos los modelos de prueba generaron más respuestas médicamente inexactas que antes del entrenamiento en el conjunto de datos comprometido. Como ejemplo, encontraron que todos los LLM informaron que no se ha demostrado la eficacia de las vacunas COVID-19. La mayoría de ellos también identificaron erróneamente el propósito de varios medicamentos comunes.
El equipo también descubrió que reducir la cantidad de documentos contaminados en el conjunto de datos de prueba a solo el 0,01% todavía daba como resultado que el 10% de las respuestas dadas por los LLM contenían datos incorrectos (y reducirlo al 0,001% todavía generaba el 7% de las respuestas). siendo incorrecto), lo que sugiere que solo se requieren unos pocos documentos de este tipo publicados en sitios web del mundo real para sesgar las respuestas dadas por los LLM.
El equipo siguió escribiendo un algoritmo capaz de identificar datos médicos en los LLM y luego utilizó referencias cruzadas para validar los datos, pero señalan que no existe una forma realista de detectar y eliminar información errónea de conjuntos de datos públicos.
Más información:
Daniel Alexander Alber et al, Los grandes modelos de lenguaje médico son vulnerables a ataques de envenenamiento de datos, Medicina de la naturaleza (2025). DOI: 10.1038/s41591-024-03445-1
© 2025 Red Ciencia X
Citación: La prueba de un ‘conjunto de datos envenenado’ muestra la vulnerabilidad de los LLM a la desinformación médica (2025, 11 de enero) recuperado el 13 de enero de 2025 de https://medicalxpress.com/news/2025-01-poisoned-dataset-vulnerability-llms-medical.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.


