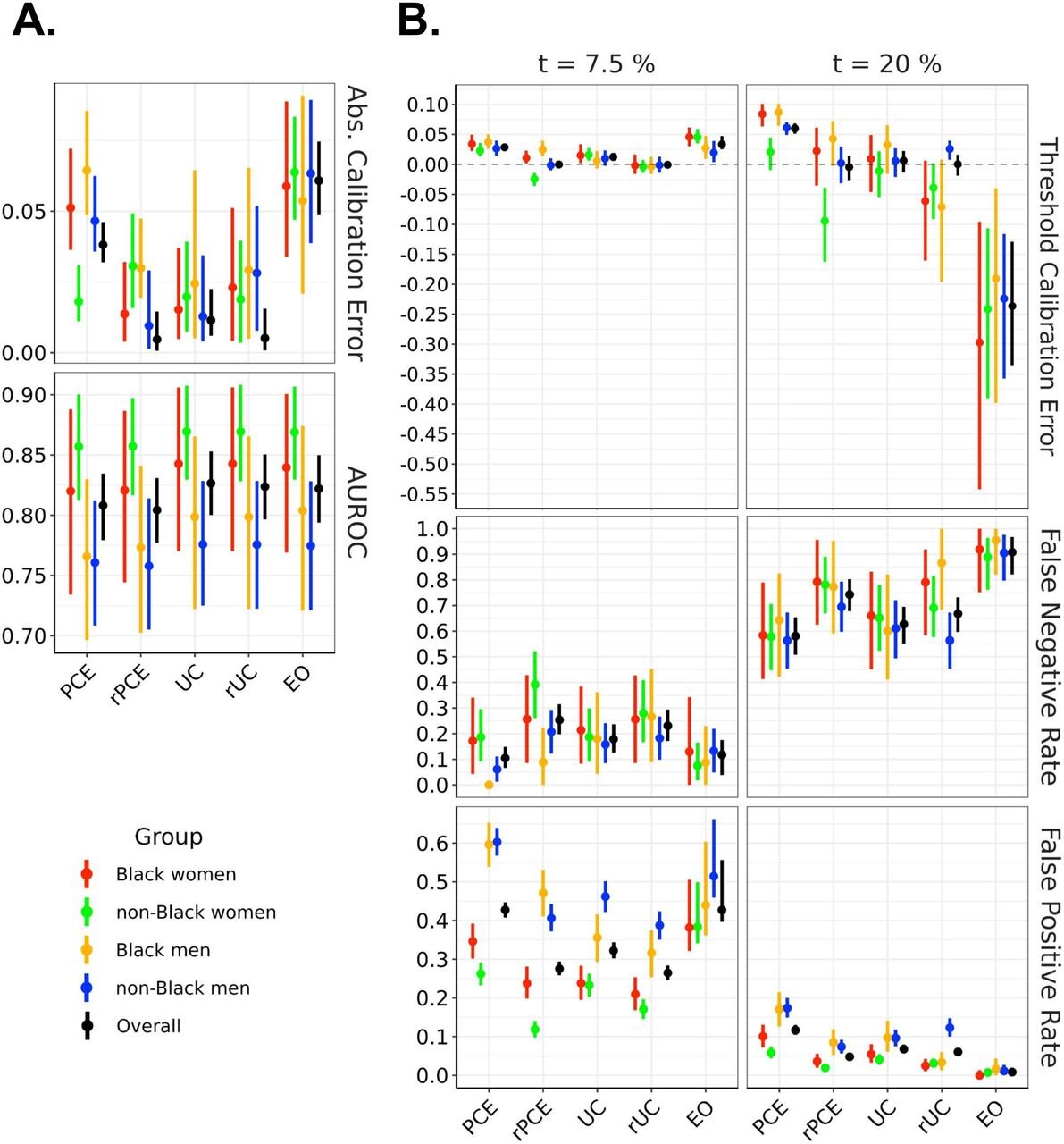
Desempeño del modelo a través de métricas de evaluación, estratificado por grupo demográfico, evaluado en el conjunto de prueba. El panel izquierdo muestra AUROC y error de calibración absoluto. El panel derecho muestra las tasas de falsos negativos, las tasas de falsos positivos y el error de calibración del umbral en dos umbrales terapéuticos (7,5 % y 20 %). EO, probabilidades igualadas; PCE, ecuaciones de cohortes agrupadas originales; rPCE, PCE revisados; rUC, modelo recalibrado; UC, modelo sin restricciones. Crédito: Informática de salud y atención de BMJ (2022). DOI: 10.1136/bmjhci-2021-100460
«¿Tratar o no tratar?» es la pregunta a la que se enfrentan continuamente los médicos. Para ayudar en la toma de decisiones, algunos recurren a modelos de predicción de riesgo de enfermedades. Estos modelos pronostican qué pacientes tienen más o menos probabilidades de desarrollar la enfermedad y, por lo tanto, podrían beneficiarse del tratamiento, según factores demográficos y datos médicos.
Con el crecimiento de estas herramientas en el campo de la medicina y especialmente en esta área de orientación clínica, los investigadores de Stanford y otros lugares están tratando de garantizar la imparcialidad de los algoritmos subyacentes de los modelos. El sesgo ha surgido como un problema importante cuando los modelos no se desarrollan utilizando datos que reflejen poblaciones diversas.
En un nuevo estudio, los investigadores de Stanford examinaron pautas clínicas importantes para la salud cardiovascular que recomiendan el uso de una calculadora de riesgo para guiar las decisiones de prescripción para mujeres negras, mujeres blancas, hombres negros y hombres blancos. Los investigadores observaron dos formas que se han propuesto para mejorar la imparcialidad de los algoritmos de la calculadora. Un enfoque, conocido como recalibración de grupo, reajusta el modelo de riesgo para cada subgrupo de pacientes para que coincida mejor con la frecuencia de los resultados observados. El segundo enfoque, llamado probabilidades igualadas, busca garantizar que las tasas de error sean similares para todos los grupos. Los investigadores encontraron que el enfoque de recalibración en general produjo la mejor coincidencia con las recomendaciones de las pautas.
Los hallazgos subrayan la importancia de construir algoritmos que tengan en cuenta el contexto completo relevante para las poblaciones a las que sirven.
«Si bien el aprendizaje automático es muy prometedor en entornos médicos y otros contextos sociales, existe el potencial de que estas tecnologías empeoren las desigualdades de salud existentes», dice Agata Foryciarz, PhD de Stanford. estudiante de informática y autor principal del estudio publicado en Informática de salud y atención de BMJ. «Nuestros resultados sugieren que evaluar la equidad de los modelos de predicción del riesgo de enfermedad puede hacer que su uso sea más responsable».
Además de Foryciarz, los investigadores incluyen al autor principal Nigam Shah, científico jefe de datos de Stanford Health Care y miembro de la facultad de Stanford HAI; Stephen Pfohl, científico de investigación de Google, y Birju Patel, especialista clínica de Google Health.
Prevención prudente
Las guías clínicas evaluadas en el estudio son para la prevención primaria de la enfermedad cardiovascular aterosclerótica. Esta condición es causada por grasas, colesterol y otras sustancias que se acumulan como las llamadas placas en las paredes de las arterias. Las placas pegajosas bloquean el flujo sanguíneo y pueden provocar resultados adversos, como accidentes cerebrovasculares e insuficiencia renal.
Las pautas, publicadas por el Colegio Estadounidense de Cardiología y la Asociación Estadounidense del Corazón, brindan recomendaciones sobre cuándo los pacientes deben comenzar a tomar medicamentos llamados estatinas, medicamentos que reducen los niveles de cierto colesterol que conducen a la acumulación arterial.
Las pautas para la enfermedad cardiovascular aterosclerótica tienen en cuenta medidas médicas que incluyen la presión arterial, los niveles de colesterol, el diagnóstico de diabetes, el tabaquismo y el tratamiento de la hipertensión, junto con la demografía del sexo, la edad y la raza. Con base en estos datos, las pautas sugieren el uso de una calculadora que luego estime el riesgo general de los pacientes de desarrollar enfermedades cardiovasculares dentro de los 10 años. Se aconseja a los pacientes identificados como de riesgo intermedio o alto de enfermedad que inicien el tratamiento con estatinas. Para los pacientes que, por el contrario, se encuentran en el límite o en un riesgo bajo de enfermedad, la terapia con estatinas podría ser innecesaria o no deseada debido a los posibles efectos secundarios de los medicamentos.
«Si se percibe que usted, como paciente, tiene un mayor riesgo del que realmente tiene, se le puede recetar una estatina que no necesita», dice Foryciarz. «Entonces, por otro lado, si se pronostica que usted tendrá un riesgo bajo pero realmente debería tomar una estatina, los médicos podrían no implementar medidas preventivas que podrían haber evitado la enfermedad cardíaca más adelante».
Las guías de práctica clínica recomiendan cada vez más a los médicos que utilicen modelos de predicción de riesgo clínico para diversas afecciones y poblaciones de pacientes. La proliferación de calculadoras de apoyo a la toma de decisiones médicas, por ejemplo, en teléfonos y otros dispositivos electrónicos utilizados en entornos clínicos, significa que tales aplicaciones suelen estar al alcance de la mano.
«Es probable que los médicos encuentren y utilicen cada vez más estas herramientas de soporte de decisiones basadas en algoritmos, por lo que es importante que los diseñadores intenten garantizar que las herramientas sean lo más justas y precisas posible», dice Foryciarz.
Evaluación de riesgos de refinación
Para su estudio, Foryciarz y sus colegas utilizaron una cohorte de más de 25 000 pacientes de 40 a 79 años de edad recopilados en varios conjuntos de datos grandes. Los investigadores compararon la incidencia real de aterosclerosis de los pacientes con las predicciones realizadas por los modelos de riesgo. Como parte de estos experimentos, los investigadores construyeron modelos utilizando los dos enfoques de recalibración de grupo y probabilidades igualadas y luego compararon las estimaciones generadas por las calculadoras del modelo con las generadas por una calculadora de modelo simple sin ajuste de equidad.
Recalibrar por separado para cada uno de los cuatro subgrupos implicó ejecutar el modelo para un subconjunto de cada subgrupo y obtener una puntuación de riesgo del porcentaje real de pacientes que desarrollaron la enfermedad, y luego ajustar el modelo subyacente para el subgrupo más amplio. Este enfoque impulsó con éxito la compatibilidad deseada del modelo con las pautas para aquellos pacientes con niveles bajos de riesgo. Por otro lado, surgieron diferencias en las tasas de error entre los subgrupos en general, especialmente en el extremo de alto riesgo.
El enfoque de probabilidades igualadas, por el contrario, requería construir un nuevo modelo predictivo que estaba limitado a producir tasas de error igualadas entre las poblaciones. En la práctica, este enfoque logra tasas similares de falsos positivos y falsos negativos en todas las poblaciones. Un falso positivo se refiere a un paciente identificado como de alto riesgo y que comenzaría con una estatina, pero que no desarrolló enfermedad cardiovascular aterosclerótica, mientras que un falso negativo se refiere a un paciente identificado como de bajo riesgo, pero que desarrolló enfermedad cardiovascular aterosclerótica. y probablemente se habría beneficiado de tomar una estatina.
Ir con este enfoque de probabilidades igualadas finalmente sesgó los niveles de umbral de decisión para los diversos subgrupos. En comparación con el enfoque de recalibración grupal, el uso de la calculadora construida teniendo en cuenta las probabilidades igualadas habría llevado a una prescripción más baja y más alta de estatinas y no podría prevenir potencialmente algunos de los resultados adversos.
La ganancia en precisión con la recalibración grupal requiere tiempo y esfuerzo adicionales para ajustar el modelo original en lugar de dejar el modelo tal como está, aunque esto sería un pequeño precio a pagar por mejores resultados clínicos. Una advertencia adicional es que dividir una población en subgrupos aumenta las posibilidades de crear un tamaño de muestra demasiado pequeño para evaluar de manera efectiva los riesgos dentro del subgrupo, mientras que también reduce la capacidad de extender las predicciones del modelo a otros subgrupos.
En general, tanto los diseñadores de algoritmos como los médicos deben tener en cuenta qué métricas de equidad usar para la evaluación y cuáles, si las hay, usar para el ajuste del modelo. También deben comprender cómo se utilizará en la práctica un modelo o una calculadora y cómo las predicciones erróneas podrían llevar a decisiones clínicas que pueden generar resultados adversos para la salud en el futuro. La conciencia del posible sesgo y un mayor desarrollo de los enfoques de equidad para los algoritmos pueden mejorar los resultados para todos, señala Foryciarz.
«Si bien no siempre es fácil identificar en cuál de los posibles subgrupos enfocarse, considerar algunos subgrupos es mejor que no considerar ninguno», dice Foryciarz. «Desarrollar algoritmos para servir a una población diversa significa que los propios algoritmos deben desarrollarse teniendo en cuenta esa diversidad».
Agata Foryciarz et al, Evaluación de la equidad algorítmica en presencia de guías clínicas: el caso de la estimación del riesgo de enfermedad cardiovascular aterosclerótica, Informática de salud y atención de BMJ (2022). DOI: 10.1136/bmjhci-2021-100460
Citación: Garantizar la equidad de los algoritmos que predicen el riesgo de enfermedad del paciente (1 de agosto de 2022) recuperado el 1 de agosto de 2022 de https://medicalxpress.com/news/2022-08-fairness-algorithms-patient-disease.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.

